PyTorch 学习笔记 (11): Transformer 模型
2025-12-30·15 min read
#PyTorch#Deep Learning#Transformer#NLP
Transformer 是现代 NLP 的基石,完全基于注意力机制,不使用循环或卷积。
核心思想
- 通过自注意力机制并行处理序列
- 大大提高了训练效率
- 能够捕捉长距离依赖
主要组件:
- Encoder (编码器):处理输入序列
- Decoder (解码器):生成输出序列
- Positional Encoding:添加位置信息
位置编码
由于自注意力没有序列位置信息,需要添加位置编码:
text
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
python
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, d_model, max_len=5000, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 创建位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 计算分母项
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
)
# 偶数位置用sin,奇数位置用cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 添加batch维度
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
"""x: (batch, seq_len, d_model)"""
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
为什么用正弦/余弦?
- 可以处理任意长度
- 相对位置可以通过线性变换得到
缩放点积注意力
python
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):
"""
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
"""
d_k = query.size(-1)
# 计算注意力分数
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 应用mask(用于decoder的自回归)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# Softmax
attention_weights = F.softmax(scores, dim=-1)
if dropout is not None:
attention_weights = dropout(attention_weights)
# 应用到value
output = torch.matmul(attention_weights, value)
return output, attention_weights
多头注意力
python
class MultiHeadAttention(nn.Module):
"""
MultiHead(Q, K, V) = Concat(head_1, ..., head_h) W^O
where head_i = Attention(QW^Q_i, KW^K_i, VW^V_i)
"""
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性投影层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 1. 线性投影
Q = self.W_q(query)
K = self.W_k(key)
V = self.W_v(value)
# 2. 分割成多头
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 3. 缩放点积注意力
attn_output, attention_weights = scaled_dot_product_attention(
Q, K, V, mask, self.dropout
)
# 4. 合并多头
attn_output = attn_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
# 5. 输出投影
output = self.W_o(attn_output)
return output, attention_weights
位置前馈网络
python
class PositionwiseFeedForward(nn.Module):
"""
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2
两个线性变换,中间有ReLU激活
通常 d_ff = 4 * d_model
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
编码器层
python
class EncoderLayer(nn.Module):
"""
Transformer编码器层
结构:
x -> Multi-Head Attention -> Add and Norm -> FFN -> Add and Norm
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Self-Attention with Residual
attn_out, _ = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_out))
# Feed-Forward with Residual
ff_out = self.feed_forward(x)
x = self.norm2(x + self.dropout2(ff_out))
return x
解码器层
python
class DecoderLayer(nn.Module):
"""
Transformer解码器层
结构:
x -> Masked Self-Attention -> Add and Norm
-> Cross-Attention -> Add and Norm
-> FFN -> Add and Norm
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# Self-Attention (带mask)
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
# Cross-Attention (query来自decoder, key/value来自encoder)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
# Masked Self-Attention
attn_out, _ = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout1(attn_out))
# Cross-Attention
attn_out, _ = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.norm2(x + self.dropout2(attn_out))
# Feed-Forward
ff_out = self.feed_forward(x)
x = self.norm3(x + self.dropout3(ff_out))
return x
Transformer 架构图
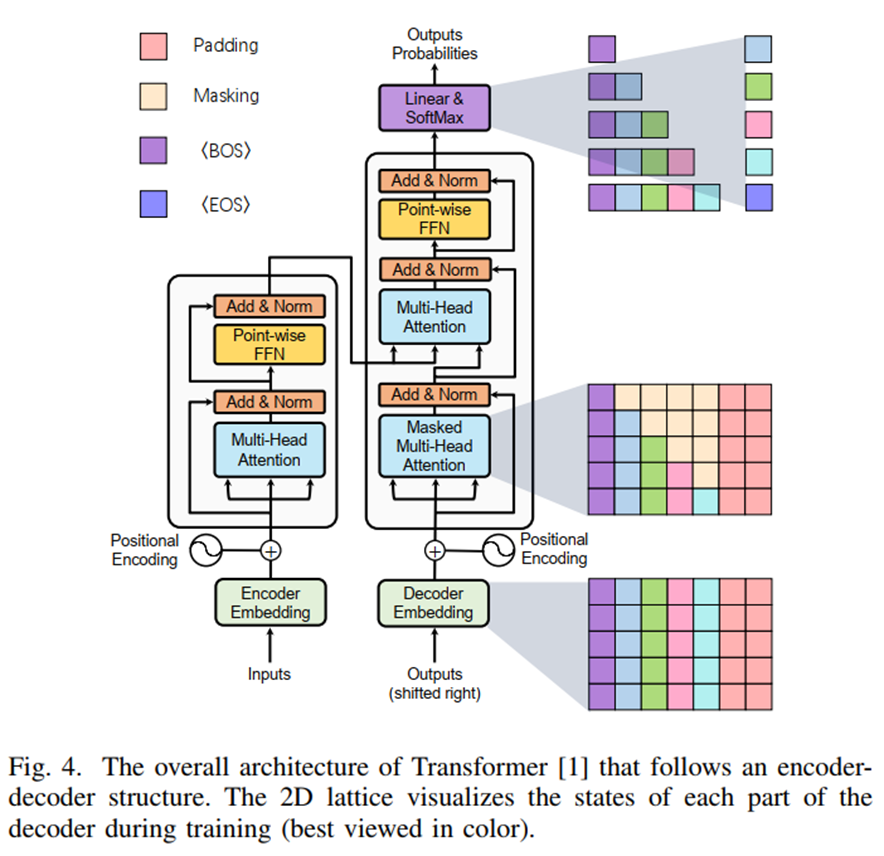
Transformer 变体
| 模型 | 架构 | 预训练任务 |
|---|---|---|
| BERT | Encoder-only | Masked Language Model |
| GPT | Decoder-only | 自回归生成 |
| T5 | Encoder-Decoder | 文本到文本 |